Analisi delle Componenti Principali
Nell'intelligenza artificiale, e in particolare nel Machine Learning, la riduzione della dimensionalità è una necessità pratica: i dati, che rappresentano ad esempio immagini, sequenze genomiche, serie finanziarie, hanno migliaia o milioni di variabili, ma spesso molta di questa informazione è ridondante o è semplice rumore.
In un dataset ad alta dimensione, i dati sono inizialmente espressi nella base canonica, per cui ogni asse è una variabile misurata. Tuttavia, questa base raramente è la più efficiente per descrivere la struttura del fenomeno.
Obiettivo della Principal Component Analysis (PCA) è trovare una nuova base ortonormale $\{\mathbf{u}_1, \mathbf{u}_2, \dots, \mathbf{u}_n\}$ tale che:
- il primo vettore \(\mathbf{u}_1\), detto prima componente principale, punti nella direzione di massima varianza, dove i dati sono più "spalmati", dove c'è più ricchezza di informazione,
- il secondo vettore \(\mathbf{u}_2\), detto seconda componente principale, sia ortogonale al primo e catturi la massima varianza rimanente,
- ... e così via.
Ad esempio data una nuvola di punti che forma un cilindro inclinato nello spazio in 3 dimensioni, le sue proiezioni sui piani della base canonica non forniscono una scomposizione adatta per una chiara ricostruzione della forma complessiva. La PCA trova come prima componente di un nuovo rierimento la direzione lungo cui la forma è più allungata, l’asse del cilindro, come seconda componente la direzione di massima variazione residua e come terza quella ortogonale alle prime due. Così proiettando la forma sulle prime due componenti principali si ottiene una vista perfettamente allineata con la struttura, una rappresentazione 2D che conserva quasi tutta la geometria.
La PCA ruota cioè la forma nello spazio per guardarla “dal punto di vista giusto”.
In statistica, la varianza totale dei dati è l'analogo dell'energia di un segnale in fisica e l'analogo dell'informazione. L'identità di Parseval ci garantisce che se cambiamo base verso una base ortonormale come quella delle componenti principali, la varianza totale rimane invariata, ovvero sappiamo esattamente quanta informazione stiamo trattando.
Se poi ad esempio le prime 3 componenti principali catturano il 95% della varianza totale, l'energia del dataset, possiamo decidere di proiettare tutti i nostri dati solo su questo sottospazio di dimensione 3 scartando le altre n-3 dimensioni.
Passiamo così da un problema computazionalmente complesso a uno meglio gestibile, eliminando il rumore solitamente assocoato alle componenti con varianza minima.
Supponiamo dunque di avere un dataset con $p$ variabili $\mathbf{x}_1, \mathbf{x}_2, \dots, \mathbf{x}_p$ (features) ciascuna composta da $n$ osservazioni $x_{1,i},x_{2,i},\dots,x_{n,i}.$ che conviene considerare centrate intorno alla media, considerare cioè $χ_{1,i}-\overline{χ_i},x_{2,i}-\overline{χ_i},\dots,χ_{n,i}-\overline{χ_i}$ piuttosto che le osservazioni originarie $\mathbf{χ}_i$, poichè così
- la varianza è $var(\mathbf{x}_i)=\frac{1}{n-1}\|\mathbf{x}_i\|^2,$
- la covarianza è $cov(\mathbf{x}_i,\mathbf{x}_j)=\frac{1}{n-1}\langle \mathbf{x}_i, \mathbf{x}_j\rangle.$
- $𝑄$ è una matrice ortogonale \(𝑄^T𝑄=𝐼\) le cui colonne sono autovettori ortonormali,
- $Λ$ è diagonale con autovalori in diagonale.
Le componenti principali dei vettori $\mathbf{x}_i$ \[ \mathbf{ξ}_i = X\mathbf{u}_i \] sono le coordinate dei dati lungo queste nuove direzioni.
Ciò ha per effetti pratici: l'eliminazione del rumore, la compressione dei dati, la visualizzazione (2D/3D).
Ad esempio: clustering più stabile, classificazione con meno overfitting, anomaly detection (outlier lontani dalle componenti principali).
Senza ortonormalità le componenti sarebbero correlate, si avrebbe informazione “doppia”
Consideriamo un esempio concreto e minimale in Python che evidenzia perché una base ortonormale è utile nel Data Mining, usando PCA su dati reali.
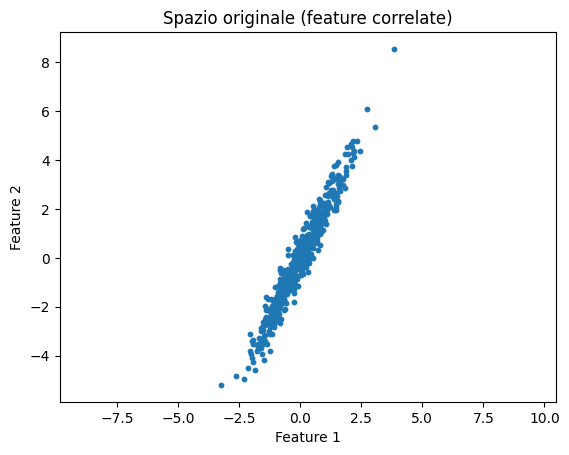
Useremo un dataset con feature correlate e faremo un confronto dopo il cambio di base ortonormale.
import matplotlib.pyplot as plt
import numpy as np
np.random.seed(42)
n = 500
x = np.random.normal(0, 1, n)
y = 2*x + np.random.normal(0, 0.5, n)
X = np.column_stack((x, y))
plt.scatter(X[:,0], X[:,1], s=10)
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.title("Spazio originale (feature correlate)")
plt.axis("equal")
plt.show()
# centramento
X_centered = X - X.mean(axis=0)
# standardizzazione (opzionale ma consigliata)
X_std = X_centered / X_centered.std(axis=0)
# Matrice di covarianza
n = X_std.shape[0]
C = (X_std.T @ X_std) / (n - 1)
print("Matrice di covarianza:\n", C)
Matrice di covarianza:
[[1.00200401 0.97134381]
[0.97134381 1.00200401]]
# Autovalori e autovettori
eigvals, eigvecs = np.linalg.eigh(C)
# Ordiniamo per autovalore decrescente:
idx = np.argsort(eigvals)[::-1]
eigvals = eigvals[idx]
eigvecs = eigvecs[:, idx]
print("Autovalori:", eigvals)
print("Autovettori (colonne):\n", eigvecs)
# ortogonalità
print("Prodotto scalare:", eigvecs[:,0] @ eigvecs[:,1])
# norma
print("Norme:", np.linalg.norm(eigvecs, axis=0))
Autovalori: [1.97334782 0.0306602 ]
Autovettori (colonne):
[[ 0.70710678 -0.70710678]
[ 0.70710678 0.70710678]]
Prodotto scalare: 0.0
Norme: [1. 1.]
# Proiezione sui nuovi assi (PCA “a mano”)
Z = X_std @ eigvecs
plt.scatter(Z[:,0], Z[:,1], s=10)
plt.xlabel("direzione di massima varianza (informazione)")
plt.ylabel("quasi solo rumore")
plt.title("Dati proiettati su base ortonormale (PCA manuale)")
plt.axis("equal")
plt.show()
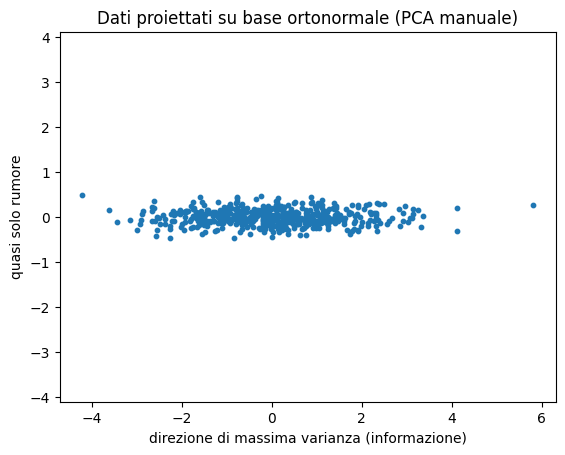
la PCA è diagonalizzazione ortogonale di 𝐶, gli autovettori sono direzioni di varianza massima, assi indipendenti per coordinate “naturali” dei dati.
Risultato tipico: clustering instabile nello spazio originale, clustering robusto nello spazio PCA dato che le distanze sono calcolate su assi indipendenti.
Z_1d = Z[:, :1] # tiene solo PC1
# Ricostruzione approssimata
X_rec = Z_1d @ eigvecs[:, :1].T
# Riportiamo alla scala originale
X_rec = X_rec * std + X.mean(axis=0)
plt.scatter(X[:,0], X[:,1], s=10, label="Originale")
plt.scatter(X_rec[:,0], X_rec[:,1], s=10, label="Ricostruito")
plt.legend()
plt.title("Compressione con base ortonormale")
plt.axis("equal")
plt.show()
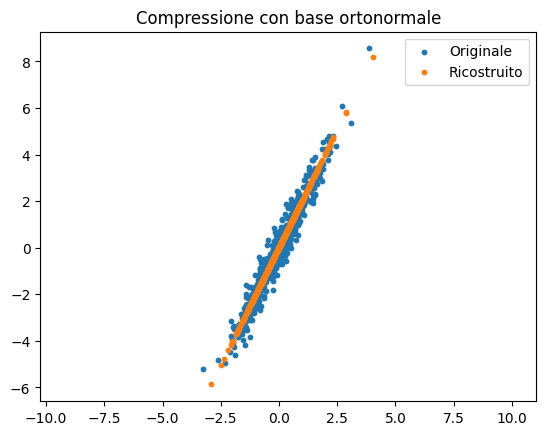
Si osserva che la struttura è preservata e il rumore è attenuato.
Quando il numero di variabili \(p\) è molto più grande del numero di osservazioni \(n\), caso estremamente importante in machine learning, genomica, elaborazione di immagini e Natural Language Processing, la PCA cambia natura in modo profondo.
La matrice di covarianza \(C\) ha almeno \(p - n\) autovalori nulli, è singolare, non è invertibile, non può avere più di \(n\) componenti principali non banali.
In alta dimensionalità, la PCA ha al massimo \(n\) componenti principali utili, anche se le variabili sono \(p\).
Gli autovettori della covarianza sono in \(\mathbb{R}^p\), ma solo \(n\) sono significativi.
La decomposizione spettrale di \(C\):
\[
C = Q \Lambda Q^\top
\]
produce \(p\) autovettori ortonormali in \(\mathbb{R}^p\) ma solo i primi \(n\) hanno autovalori non nulli, gli altri \(p-n\) sono direzioni “vuote”, senza varianza. Quindi non si ottiene una base utile di \(\mathbb{R}^p\) ma una base ortonormale dello spazio delle variabili con moltissime direzioni degeneri.
Dunque la PCA classica diventa inefficiente e numericamente instabile:
calcolare \(X^\top X\) quando \(p\) è enorme costa molto, è numericamente instabile, produce una matrice gigantesca \(p \times p\) ma di rango massimo \(n\).
In alta dimensionalità si usa la Singular Value Decomposition (SVD) della matrice dei dati centrata:
\[
X_c = U \Sigma V^\top.
\]
dove
- \(U \in \mathbb{R}^{n \times n}\) è una matrice unitaria complessa con colonne ortonormali,
- \(V \in \mathbb{R}^{p \times p}\) ha colonne ortonormali,
- \(\Sigma\in \mathbb{R}^{n \times p}\) è matrice rettangolare diagonale n×n con numeri reali non negativi sulla diagonale con \(n\) valori singolari non nulli.
In alta dimensionalità lo spazio delle osservazioni ha dimensione \(n\), quello delle variabili ha dimensione \(p\), ma i dati vivono in un sottospazio di dimensione al massimo \(n\).
n, p = 5, 20
# Matrice dei dati: n osservazioni, p variabili
X = np.random.randn(n, p)
# Centriamo i dati
means = X.mean(axis=0)
Xc = X - means
# SVD della matrice centrata Xc = U Σ V^T
U, S, Vt = np.linalg.svd(Xc, full_matrices=False)
print("\nShape U:", U.shape) # (n, n)
print("Shape S:", S.shape) # (n,)
print("Shape Vt:", Vt.shape) # (n, p)
# Le componenti principali sono le colonne di:
Z = U * S # equivalente a Xc @ V
print("\nShape delle componenti principali Z:", Z.shape)
# Gli autovalori della covarianza sono i quadrati dei valori singolari divisi per (n-1)
eigenvalues = (S**2) / (n - 1)
print("\nAutovalori della matrice di covarianza:")
print(eigenvalues)
# Gli Autovettori della matrice di covarianza sono le righe di Vt (o le colonne di V)
V = Vt.T
print("\nAutovettori (prime n colonne):")
print(V[:, :n])
# Verifica: ricostruzione dei dati usando r componenti
r = 4 # numero di componenti principali da usare
X_reconstructed = (Z[:, :r] @ Vt[:r, :]) + means
print(f"\nErrore di ricostruzione con r={r}:")
print(np.linalg.norm(X - X_reconstructed))
Shape U: (5, 5)
Shape S: (5,)
Shape Vt: (5, 20)
Shape delle componenti principali Z: (5, 5)
Autovalori della matrice di covarianza:
[7.31722163e+00 6.18938551e+00 4.68280120e+00 2.56442375e+00
8.31520253e-32]
Autovettori (prime n colonne):
[[ 0.04572265 0.53665652 0.24615341 -0.38383858 0.46972641]
[-0.3376726 -0.02852036 0.04808752 -0.11584609 0.14034001]
[-0.40960323 0.10480965 -0.06085435 -0.15097373 -0.41288986]
[ 0.20520548 0.6762924 -0.18846731 0.38110336 -0.28422551]
[-0.41520887 0.0657058 -0.12852313 -0.08808671 0.05787502]
[-0.08514453 -0.15260464 0.53647579 0.21172355 0.05320373]
[-0.4073465 0.18576666 0.16035429 0.14919888 0.15456555]
[ 0.16360998 -0.02032174 0.00106838 0.03282984 -0.07030414]
[-0.29242931 -0.02539709 -0.41946588 -0.13413865 0.07789497]
[-0.23588003 -0.08704427 -0.07365104 0.0551102 -0.15148796]
[-0.04058434 -0.04133571 -0.05647549 -0.36623549 -0.05060532]
[-0.12614802 0.15303172 0.12832316 0.03765869 0.27291606]
[ 0.0445711 0.07117331 0.21812718 -0.41823052 -0.39784229]
[-0.16484465 0.15561493 0.47345075 0.0639951 -0.38359472]
[ 0.00759172 0.04507105 0.12501093 -0.11101053 -0.09951448]
[-0.07975892 0.07072386 0.06187088 0.26658094 0.14147132]
[-0.20923797 0.23903671 -0.22327796 0.11406005 -0.09119579]
[-0.23399585 -0.15098856 0.06102879 0.39620141 0.07193698]
[-0.09253467 0.07731098 0.08793532 -0.07683922 0.00387784]
[-0.01624055 -0.15724244 0.11958425 0.02057298 -0.13593626]]
Errore di ricostruzione con r=4:
1.1389124819911328e-14
La tecnica è usata in recommender systems (latent factors), topic modeling (LSA), text mining (TF-IDF + SVD).
Una interpretazione consiste nel considerare gli assi latenti come “concetti” indipendenti e ogni documento/utente è una combinazione ortogonale di essi.
Alcune applicazioni sono le seguenti.
- Negli anni '90, la PCA veniva usata per creare le "Eigenfaces". Un'immagine di un volto con 10.000 pixel veniva proiettata su una base ortonormale di "volti base". Bastavano poche decine di queste proiezioni (i coefficienti) per identificare una persona, riducendo drasticamente lo spazio di archiviazione e la velocità di confronto.
- Nei moderni modelli di linguaggio, le parole sono rappresentate in spazi vettoriali ad altissima dimensione. Per visualizzare come il modello "pensa" o per velocizzare i calcoli, si usano proiezioni ortogonali per ridurre queste dimensioni a poche centinaia, mantenendo le relazioni semantiche tra le parole.
- Molte tecniche di ottimizzazione delle reti neurali (come il Pruning o la Low-rank factorization) utilizzano la scomposizione in basi ortonormali per identificare quali pesi della rete sono meno "energetici" e possono essere rimossi senza che la capacità predittiva del modello ne risenta significativamente.
Bibliografia
- Build a PCA machine learning model in Python,by Michael Attard
- A Tutorial on Principal Component Analysis, by Jonathon Shlens
- Introduzione alla PCA in Python, su diariodiunanalista.it