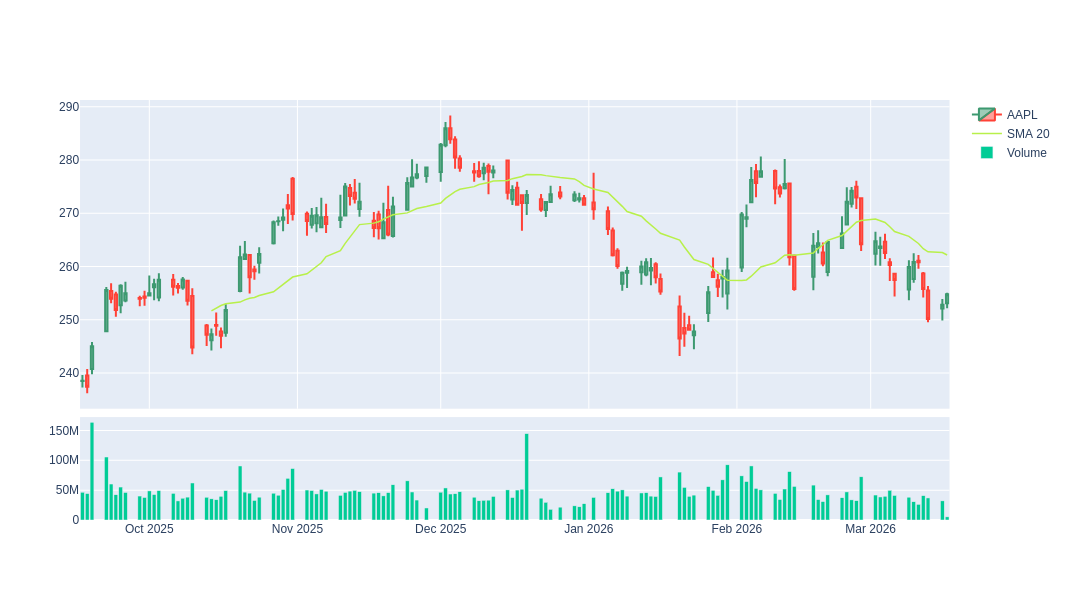
In:
import yfinance as yf
import pandas as pd
# Metodo 1: download diretto (più veloce per singolo ticker)
df = yf.download(
"AAPL",
start="2022-01-01",
end="2024-01-01",
interval="1d", # 1m, 5m, 15m, 1h, 1d, 1wk, 1mo
auto_adjust=True # prezzi aggiustati per split e dividendi
)
# Metodo 2: oggetto Ticker (più funzionale)
ticker = yf.Ticker("AAPL")
df = ticker.history(period="2y", interval="1d")
# Metadati aziendali
info = ticker.info
print(f"Settore: {info['sector']}")
print(f"Capitaliz.: ${info['marketCap']/1e12:.2f}T")
print(f"P/E ratio: {info['trailingPE']:.1f}")
print(f"52w High: ${info['fiftyTwoWeekHigh']:.2f}")