Prima di rischiare denaro reale è bene simulare la strategia scelta su dati storici. Il backtesting misura performance, rischio e robustezza, serve per eliminare le strategie perdenti prima di andare live.
Intermedio~120 minbacktraderpandas
Cos'e il backtesting
Il backtesting risponde a: “Se avessi usato questa strategia negli ultimi N anni, quanto avrei guadagnato o perso?” Non garantisce performance future, ma elimina strategie palesemente non profittevoli prima di aprire un conto reale.
✅ Cosa misura
Rendimento totale, CAGR, Sharpe ratio, win rate, massimo drawdown, profit factor. Ogni metrica racconta un aspetto diverso della robustezza della strategia.
⚠️ Cosa non garantisce
Slippage reale, impatto di mercato, liquidità in stress, regime change. Un backtest ottimista non implica profitti futuri. La robustezza si misura out-of-sample.
Attenzione — Overfitting
Ottimizzare una strategia su dati storici finché appare perfetta è il modo piu rapido per perdere soldi live. Usa sempre un test set separato che non tocchi durante lo sviluppo.
Motore di backtesting in puro pandas
Prima delle librerie, costruiamo un motore minimale. Strategia: SMA Crossover — compra quando SMA20 > SMA50, esci quando si inverte.
Backtrader è un framework Python ricco di funzionalità per il backtesting e il trading che permette di concentrarsi sulla scrittura di strategie di trading, indicatori e analizzatori riutilizzabili. Invece di dover dedicare tempo alla creazione di infrastrutture, gestisce automaticamente esecuzione ordini, commissioni, sizing e analizzatori statistici. Perfetto per strategie multi-asset e sistemi complessi.
In:
import backtrader as bt
class SMACross(bt.Strategy):
params = (('fast', 20), ('slow', 50),)
def __init__(self):
self.fast = bt.ind.SMA(self.data, period=self.p.fast)
self.slow = bt.ind.SMA(self.data, period=self.p.slow)
self.up = bt.ind.CrossUp(self.fast, self.slow)
self.down = bt.ind.CrossDown(self.fast, self.slow)
self.crossover = bt.ind.CrossOver(self.fast, self.slow)
self.order = None # To keep track of pending orders
def next(self):
if self.order: # Check if an order is pending
return
if not self.position: # Not in the market
if self.crossover > 0: # fast crosses slow upwards
# self.log.info(f'BUY CREATE: {self.data.datetime.date(0)} - Close: {self.data.close[0]:.2f}')
self.order = self.buy(size=100) # Buy 100 shares
else: # In the market
if self.crossover < 0: # fast crosses slow downwards
# self.log.info(f'SELL CREATE: {self.data.datetime.date(0)} - Close: {self.data.close[0]:.2f}')
self.order = self.close() # Close existing position
def notify_order(self, order):
if order.status in [order.Submitted, order.Accepted]:
# Order has been submitted/accepted - no notification on this
return
# Check if an order has been completed
if order.status in [order.Completed]:
if order.isbuy():
# self.log.info(f'BUY EXECUTED, Price: {order.executed.price:.2f}, Cost: {order.executed.value:.2f}, Comm: {order.executed.comm:.2f}')
pass
elif order.issell():
# self.log.info(f'SELL EXECUTED, Price: {order.executed.price:.2f}, Cost: {order.executed.value:.2f}, Comm: {order.executed.comm:.2f}')
pass
self.bar_executed = len(self)
elif order.status in [order.Canceled, order.Margin, order.Rejected]:
# self.log.info('Order Canceled/Margin/Rejected')
pass
# Clear pending order
self.order = None
cerebro = bt.Cerebro()
cerebro.addstrategy(SMACross)
cerebro.broker.set_cash(10_000)
cerebro.broker.setcommission(commission=0.001)
raw = yf.download("AAPL", start="2019-01-01", end="2024-01-01")
# Flatten MultiIndex columns to single-level strings expected by backtrader
# Based on the kernel state, the columns are already transformed to 'close_aapl', 'high_aapl', etc.
# This block correctly transforms the column names from MultiIndex to single-level, but `backtrader` still needs explicit mapping.
new_columns = []
for col_tuple in raw.columns:
if col_tuple[0] == 'Price':
new_columns.append(col_tuple[1].lower()) # Convert to lowercase (e.g., 'Close' -> 'close')
elif col_tuple[0] == 'Volume':
new_columns.append('volume') # Convert to lowercase
else:
new_columns.append('_'.join(col_tuple).lower()) # Fallback for unexpected columns
raw.columns = new_columns
cerebro.adddata(
bt.feeds.PandasData(
dataname=raw,
datetime=None, # Index is datetime
open='open_aapl',
high='high_aapl',
low='low_aapl',
close='close_aapl',
volume='volume',
openinterest=None # Not available in yfinance data
)
)
cerebro.addanalyzer(bt.analyzers.SharpeRatio, _name='sharpe')
cerebro.addanalyzer(bt.analyzers.DrawDown, _name='dd')
print(f"Capitale iniziale: ${cerebro.broker.getvalue():,.0f}")
res = cerebro.run()[0]
print(f"Capitale finale: ${cerebro.broker.getvalue():,.0f}")
# Check if sharpe ratio was calculated before printing
sharpe_ratio_analysis = res.analyzers.sharpe.get_analysis()
if 'sharperatio' in sharpe_ratio_analysis and sharpe_ratio_analysis['sharperatio'] is not None:
print(f"Sharpe: {sharpe_ratio_analysis['sharperatio']:.2f}")
else:
print("Sharpe: N/A (No trades or insufficient data)")
max_dd_analysis = res.analyzers.dd.get_analysis()
if max_dd_analysis and max_dd_analysis.max.drawdown is not None:
print(f"Max DD: {max_dd_analysis.max.drawdown:.1f}%")
else:
print("Max DD: N/A (No trades or insufficient data)")
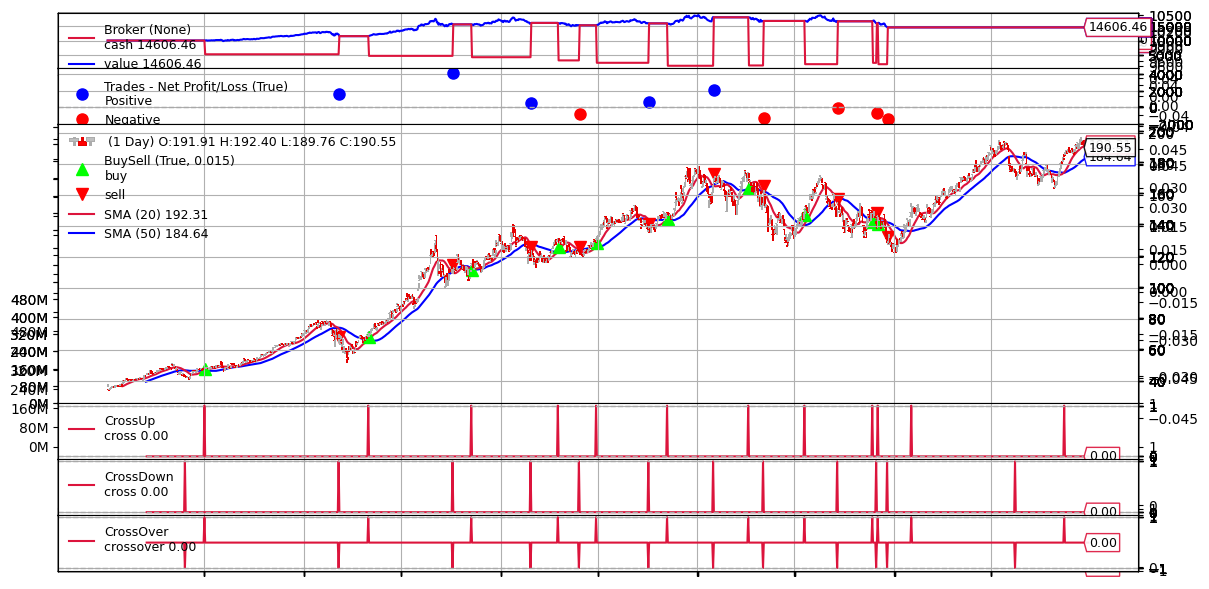
figs = cerebro.plot(iplot=False, style='candlestick')
plt.savefig('backtest.png', dpi=100, bbox_inches='tight')
from IPython.display import Image
Image('backtest.png')
Out:
/tmp/ipykernel_351/3379643488.py:55: FutureWarning: YF.download() has changed argument auto_adjust default to True
raw = yf.download("AAPL", start="2019-01-01", end="2024-01-01")
[*********************100%***********************] 1 of 1 completed
Capitale iniziale: $10,000
Capitale finale: $14,606
Sharpe: 0.43
Max DD: 22.9%
Le insidie più comuni
Insidia
Descrizione
Rimedio
Look-ahead bias
Usare dati futuri per segnali passati (stesso giorno del Close)
Usa sempre signal.shift(1)
Survivorship bias
Testare solo su azioni ancora quotate, ignorando i fallimenti
Dataset point-in-time o indici storici completi
Overfitting
Ottimizzare parametri fino alla perfezione sul train set
Walk-forward, out-of-sample rigoroso
Slippage ignorato
Assumere esecuzione esatta al prezzo di segnale
Aggiungi 0.05–0.1% per trade
Costi non inclusi
Non considerare commissioni, spread, tasse
cerebro.broker.setcommission(0.001)
Look-ahead bias: il piu subdolo
Calcolare la SMA e applicare il segnale allo stesso giorno è un errore fatale: sai il valore della SMA solo a fine giornata, quindi il trade avviene al piu presto il giorno dopo. Usa .shift() — sempre.
Walk-Forward Optimization
La walk-forward divide il dataset in finestre consecutive: su ciascun periodo (in-sample) si ottimizzano i parametri valutando out-of-sample. È il metodo più robusto per testare la stabilità nel tempo.
In:
df = yf.download("AAPL", start="2015-01-01", end="2024-01-01", auto_adjust=True)
df.columns = [col[0] for col in df.columns]
df["ret"] = df.Close.pct_change()
def backtest(data, f, s):
d = data.copy()
# Segnale: 1 quando fast MA > slow MA (trend rialzista) 0 altrimenti (non investi)
d["sig"] = (d.Close.rolling(f).mean() > d.Close.rolling(s).mean()).astype(int)
# Ritorna strategia: segnale shiftato * rendimento, poi annualizzato
return (d.ret * d.sig.shift()).dropna().mean() * 252
candidati = [(f,s) for f in [10,20,30] for s in [50,100,200] if f < s]
for a in range(2017, 2024):
train = df[f"{a-2}-01-01":f"{a}-01-01"] # due anni prima
test = df[f"{a}-01-01":f"{a}-07-01"] # sei mesi dopo
best = max(candidati, key=lambda p: backtest(train, *p))
oos = backtest(test, *best)
print(f"anno: {a}, best params: {best}, oos_cagr: {round(oos*100,1)}")
Out:
[*********************100%***********************] 1 of 1 completed
anno: 2017, best params: (20, 200), oos_cagr: 0.0
anno: 2018, best params: (10, 100), oos_cagr: -3.2
anno: 2019, best params: (20, 200), oos_cagr: 0.0
anno: 2020, best params: (20, 50), oos_cagr: 45.1
anno: 2021, best params: (30, 50), oos_cagr: -8.6
anno: 2022, best params: (30, 100), oos_cagr: 0.0
anno: 2023, best params: (10, 100), oos_cagr: 23.7
Diventa più robusto aggiungendo altre metriche, un filtro di selezione più robusto e con valutazione della stabilità dei parametri.
In:
from collections import Counter
# Scarica dati
df = yf.download("AAPL", start="2015-01-01", end="2024-01-01", auto_adjust=True)
df.columns = [col[0] for col in df.columns]
df["ret"] = df.Close.pct_change()
def backtest(data, f, s):
"""Versione base: ritorna CAGR annualizzato"""
d = data.copy()
d["sig"] = (d.Close.rolling(f).mean() > d.Close.rolling(s).mean()).astype(int)
return (d.ret * d.sig.shift()).dropna().mean() * 252
def backtest_avanzato(data, f, s):
"""Versione con metriche multiple"""
d = data.copy()
d["sig"] = (d.Close.rolling(f).mean() > d.Close.rolling(s).mean()).astype(int)
d["strat_ret"] = d.ret * d.sig.shift()
returns = d["strat_ret"].dropna()
if len(returns) == 0:
return {'cagr': -999, 'sharpe': -999, 'trades': 0}
cagr = returns.mean() * 252
sharpe = returns.mean() / returns.std() * np.sqrt(252) if returns.std() > 0 else 0
trades = (d["sig"].diff() != 0).sum()
return {'cagr': cagr, 'sharpe': sharpe, 'trades': trades}
def score_composito(metriche):
"""Metrica composita per selezionare il miglior modello"""
# Preferiamo Sharpe alto, ma penalizziamo troppi trades
return metriche['sharpe'] - (metriche['trades'] / 100) * 0.1
# Griglia parametri
candidati = [(f,s) for f in [10,20,30] for s in [50,100,200] if f < s]
# Walk-forward analysis
risultati = []
print("="*70)
print("WALK-FORWARD ANALYSIS")
print("="*70)
for a in range(2017, 2024):
train = df[f"{a-2}-01-01":f"{a}-01-01"]
test = df[f"{a}-01-01":f"{a}-07-01"]
if len(train) == 0 or len(test) == 0:
continue
# Ottimizzazione su train (usa metrica composita)
best_params = None
best_score = -np.inf
for f,s in candidati:
metriche = backtest_avanzato(train, f, s)
score = score_composito(metriche)
if score > best_score:
best_score = score
best_params = (f, s)
# Test su out-of-sample
perf_oos = backtest_avanzato(test, *best_params)
risultati.append({
'anno': a,
'params': best_params,
'oos_cagr': perf_oos['cagr'],
'oos_sharpe': perf_oos['sharpe'],
'trades': perf_oos['trades']
})
print(f"{a}: params={best_params}, cagr={perf_oos['cagr']*100:5.1f}%, sharpe={perf_oos['sharpe']:.2f}, trades={perf_oos['trades']}")
# Analisi finale
print("\n" + "="*70)
print("ANALISI FINALE")
print("="*70)
df_ris = pd.DataFrame(risultati)
print(f"CAGR medio OOS: {df_ris['oos_cagr'].mean()*100:.1f}%")
print(f"CAGR std OOS: {df_ris['oos_cagr'].std()*100:.1f}%")
print(f"Sharpe medio OOS: {df_ris['oos_sharpe'].mean():.2f}")
print(f"Finestre positive: {(df_ris['oos_cagr'] > 0).sum()}/{len(df_ris)}")
# Stabilità parametri
params_più_comuni = Counter([str(p) for p in df_ris['params']]).most_common(3)
print(f"\nParametri più stabili nel tempo:")
for params, count in params_più_comuni:
print(f" {params}: {count} finestre")
# Verdetto
if df_ris['oos_cagr'].mean() > 0 and (df_ris['oos_cagr'] > 0).sum() > len(df_ris)*0.7:
print("\n✅ VERDETTO: Sistema ROBUSTO")
elif df_ris['oos_cagr'].mean() > 0:
print("\n🟡 VERDETTO: Sistema INSTABILE ma potenzialmente profittevole")
else:
print("\n🔴 VERDETTO: Sistema NON ROBUSTO - evita di usarlo")
Una strategia ottiene Sharpe 2.4 sul train set (2015–2020) ma solo 0.2 sul test set (2021–2024). Cosa indica?
A La strategia funziona, il test set e semplicemente un periodo difficile
B Bisogna ottimizzare ulteriormente sul test set
C Probabile overfitting: la strategia ha memorizzato il train set
D Il test set e troppo breve per essere significativo
ESERCIZIOBacktesta una strategia RSI mean-reversion
Usando il motore pandas, implementa una strategia RSI: compra quando RSI(14) scende sotto 30, esci quando supera 70. Confronta con buy&hold su AAPL, MSFT, SPY negli ultimi 5 anni.
Calcola Sharpe, max drawdown, profit factor per ciascun ticker
Prova periodi RSI 7, 14, 21 — quale da il miglior Sharpe out-of-sample?
Aggiungi 0.1% di costo per trade e osserva l'impatto sulle metriche
Bonus: usa backtrader con addanalyzer per ottenere le stesse metriche