Nel 1993 è stato diffuso il Codice di stile della comunicazione scritta ad uso
delle amministrazioni pubbliche, pubblicato a cura del Dipartimento della Funzione
Pubblica ([AA.VV. 1993]). Scopo del Codice di
stile è dare alcuni elementi di base per sensibilizzare la Pubblica Amministrazione
sul problema della leggibilità, fornendo anche indicazioni pratiche ed esempi.
È la prima pubblicazione di questo genere prodotta in Italia da organi dello Stato, e
prende esempio da testi analoghi già circolanti da anni in altri paesi (come il Manual
de Estilo del Lenguaje Administrativo in Spagna).
Nella parte prima del Codice di stile viene illustrato lo stretto rapporto tra
diritti dei cittadini e chiarezza dei testi, attraverso l'analisi del linguaggio delle
leggi e delle Pubbliche Amministrazioni. Questo aspetto del rapporto Stato - cittadino è
ormai universalmente riconosciuto di fondamentale importanza, e costituisce per il nostro
Paese un primato negativo.
Nella parte seconda sono descritti studi ed esperienze sul linguaggio della Pubblica
Amministrazione, ed è citato un lavoro di analisi realizzato con Èulogos.
L'analisi, svolta da Nicola Mastidoro e Maurizio Amizzoni, e coordinata da Elisabetta
Zuanelli con la collaborazione di Maria Emanuela Piemontese, ha preso in esame un corpus di circa 90.000 occorrenze composto da
alcune centinaia di testi (lettere, circolari, ecc.) e ha prodotto due risultati
principali: analisi rispetto al Vocabolario di Base
e definizione di un primo elenco di lemmi ed espressioni del linguaggio della Pubblica
Amministrazione. Questa è stata la prima ricerca del genere condotta in Italia, sia per
dimensione del corpus che per strumenti e risultati, e costituisce un importante
precedente per futuri sviluppi in questo settore. Per lo svolgimento della ricerca è
stato scelto Èulogos perché:
- consente di lemmatizzare il corpus confrontandolo anche con il VdB. Ciò consente di valutare la leggibilità
lessicale dei testi del corpus;
- permette di produrre automaticamente liste di frequenza e materiale di sintesi,
mantenendo i collegamenti con il corpus;
- grazie alle particolari caratteristiche del Vocabolario di Sistema di Èulogos,
i nuovi lemmi incontrati durante l'analisi sono stati utilizzati per definire un primo
nucleo di un lemmario della Pubblica Amministrazione, che può essere aggiornato e
integrato continuamente.
- Èulogos permette di analizzare i testi per intero e raccolti in un unico corpus, nel quale rimangono singolarmente
individuati.
- È in studio una versione di Èulogos dedicata alla Pubblica Amministrazione,
fatta in modo da assistere durante la redazione dei testi.
 Corpus
Corpus
- Un corpus è una raccolta ordinata di testi. In linguistica si intende una
raccolta ordinata di testi che sia rappresentativa di una lingua o del linguaggio di un
particolare settore. Per fare in modo che la raccolta sia rappresentativa, si fissano
criteri ben precisi per le fonti dalle quali attingere e per i criteri di scelta
all'interno delle fonti.
Per esempio, se si vuole analizzare il linguaggio dei quotidiani, bisogna raccogliere una
grande quantità di articoli, assicurandosi che siano presenti in proporzione la maggior
quantità possibile di tipi di linguaggio dei quotidiani.
- La buona qualità dei risultati di un lavoro di analisi linguistica dipende molto dalla
buona definizione del corpus.
- Con Èulogos è possibile definire e analizzare corpus di grandi
dimensioni. Inoltre, Èulogos permette di identificare i singoli elementi del corpus
(nell'esempio di prima, si possono identificare i singoli articoli) anche nei risultati
delle analisi (liste di frequenza, liste dei segmenti ripetuti, grafici, ecc.). Grazie a
questa caratteristica, Èulogos permette di raggruppare gli elementi di uno stesso corpus
in molti modi, attraverso una finestra interattiva.
- Infine, Èulogos consente di associare agli elementi di un corpus anche
informazioni aggiuntive, da utilizzare come criteri di selezione durante lo svolgimento di
analisi e calcoli.
Indici di leggibilità: Gulpease e Flesch
- Un indice di leggibilità è una formula matematica che attraverso un calcolo statistico
è in grado di predire la reale difficoltà di un testo in base a una scala predefinita di
valori.
- Per definire la formula di un indice di leggibilità si può tener conto di diverse variabili
linguistiche, cioè della misura di alcuni parametri del testo. Le variabili
linguistiche più semplici sono, per esempio, lunghezza media delle parole e lunghezza
media delle frasi.
Vi sono variabili linguistiche che sono indipendenti dal contenuto del testo, come appunto
le due citate, oppure variabili linguistiche legate al lessico, alla struttura del
periodo, ecc.
- Sono state definite molte formule per la predizione della leggibilità, ma quelle che
hanno avuto maggiore successo sono quelle che considerano variabili linguistiche di facile
calcolo, come per esempio la lunghezza delle parole e delle frasi.
Per lo stesso motivo, i programmi che calcolano automaticamente il valore delle formule si
limitano, nella maggior parte delle applicazioni, a formule semplici.
L'indice di Flesch
- La formula di leggibilità che ha avuto maggior successo e diffusione nel mondo è
quella di Rudolf Flesch, nota come Formula di Flesch. Essa considera solo due
variabili linguistiche: lunghezza media delle parole espressa in sillabe per
parola, e lunghezza media delle frasi espressa in parole per frase.
 La formula di Flesch,
che deve la sua diffusione proprio alla sua semplicità, ha però due inconvenienti: il
primo è prodotto dal fatto che la formula è stata progettata per l'inglese ed è,
quindi, tarata sulla struttura morfologica e sillabica di questa lingua; il secondo è
rappresentato dal problema del conteggio delle sillabe. Infatti, questo tipo di calcolo si
mostra particolarmente complesso nell'ambito della lingua italiana, poiché esso non è
completamente formalizzabile mediante regole di portata generale, se non ricorrendo a
stime di tipo statistico, il cui limite, purtroppo è quello di non poter descrivere e
riprodurre esattamente la sillabazione delle singole parole di un testo. In particolare,
nel campo della sillabazione le difficoltà maggiori sono prodotte dall'accentazione e
dalla presenza di dittonghi.
La formula di Flesch,
che deve la sua diffusione proprio alla sua semplicità, ha però due inconvenienti: il
primo è prodotto dal fatto che la formula è stata progettata per l'inglese ed è,
quindi, tarata sulla struttura morfologica e sillabica di questa lingua; il secondo è
rappresentato dal problema del conteggio delle sillabe. Infatti, questo tipo di calcolo si
mostra particolarmente complesso nell'ambito della lingua italiana, poiché esso non è
completamente formalizzabile mediante regole di portata generale, se non ricorrendo a
stime di tipo statistico, il cui limite, purtroppo è quello di non poter descrivere e
riprodurre esattamente la sillabazione delle singole parole di un testo. In particolare,
nel campo della sillabazione le difficoltà maggiori sono prodotte dall'accentazione e
dalla presenza di dittonghi.
 Il fatto che la formula è
nata per l'inglese è stato affrontato da Roberto Vacca, il quale, nel 1972, ha adattato i
parametri della formula alla lingua italiana (vedi [Franchina-Vacca 1986]). Della formula esiste
anche un secondo adattamento, realizzato da Vacca nel 1986, dove: Facilità di lettura
= 217 - 1,3 W - 0,6 S. Il nuovo adattamento nasce da un'ipotesi di Vacca, autore
bilingue di uno stesso testo in lingua italiana e in lingua inglese. Secondo questa
ipotesi i due testi avrebbero dovuto avere lo stesso indice di leggibilità per il fatto
che entrambi trattavano lo stesso argomento ed erano stati scritti dallo stesso autore. Ma
in base agli esperimenti condotti dal Gruppo Universitario Linguistico-Pedagogico risulta
che i dati forniti dall'applicazione della formula del 1972 sono più attendibili di
quelli derivati dall'applicazione della formula del 1986.
Il fatto che la formula è
nata per l'inglese è stato affrontato da Roberto Vacca, il quale, nel 1972, ha adattato i
parametri della formula alla lingua italiana (vedi [Franchina-Vacca 1986]). Della formula esiste
anche un secondo adattamento, realizzato da Vacca nel 1986, dove: Facilità di lettura
= 217 - 1,3 W - 0,6 S. Il nuovo adattamento nasce da un'ipotesi di Vacca, autore
bilingue di uno stesso testo in lingua italiana e in lingua inglese. Secondo questa
ipotesi i due testi avrebbero dovuto avere lo stesso indice di leggibilità per il fatto
che entrambi trattavano lo stesso argomento ed erano stati scritti dallo stesso autore. Ma
in base agli esperimenti condotti dal Gruppo Universitario Linguistico-Pedagogico risulta
che i dati forniti dall'applicazione della formula del 1972 sono più attendibili di
quelli derivati dall'applicazione della formula del 1986.
Il secondo problema, quello delle sillabe, è ancora aperto.
L'indice GULPEASE
- Nel 1982 il GULP - Gruppo universitario linguistico pedagogico, presso l'Istituto
di Filosofia dell'Università degli studi di Roma «La Sapienza» - ha definito una nuova
formula, la formula GULPEASE, partendo direttamente dalla lingua italiana (vedi [Lucisano-Piemontese 1988] e [Lucisano 1992]).
 La formula è stata
determinata verificando con una serie di test la reale comprensibilità di un corpus di
testi. La verifica è stata fatta su diversi tipi di lettore, e accanto alla
determinazione della formula è stata definita una scala d'interpretazione dei valori
restituiti dalla formula stessa. La scala mette in relazione i valori restituiti dalla
formula con il grado di scolarizzazione del lettore.
La formula è stata
determinata verificando con una serie di test la reale comprensibilità di un corpus di
testi. La verifica è stata fatta su diversi tipi di lettore, e accanto alla
determinazione della formula è stata definita una scala d'interpretazione dei valori
restituiti dalla formula stessa. La scala mette in relazione i valori restituiti dalla
formula con il grado di scolarizzazione del lettore. 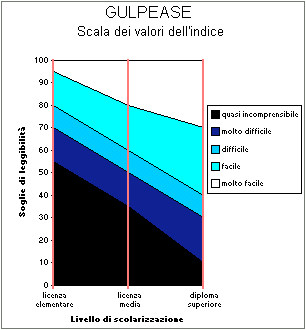 Per esempio, un testo con indice GULPEASE 60 è: molto
difficile per chi ha la licenza elementare, difficile per chi ha la licenza media, facile
per chi ha un diploma superiore.
Per esempio, un testo con indice GULPEASE 60 è: molto
difficile per chi ha la licenza elementare, difficile per chi ha la licenza media, facile
per chi ha un diploma superiore.
- La formula GULPEASE, oltre ad essere la prima formula di leggibilità tarata
direttamente sulla lingua italiana, ha anche il vantaggio di calcolare la lunghezza delle
parole il lettere, e non più in sillabe.
Proprio questa caratteristica ci ha consentito di realizzare in Èulogos una
versione informatizzata della formula con un buon livello di affidabilità.
- Il calcolo automatico di una formula di leggibilità impone di affrontare non pochi
problemi, dovuti essenzialmente alla cecità dell'elaboratore elettronico rispetto al
contenuto del testo. Il problema maggiore è la punteggiatura: per esempio, per calcolare
la lunghezza delle frasi bisogna stabilire dove inizia e dove finisce ogni frase, e in
molti casi è tutt'altro che semplice farlo (basti pensare ai molteplici usi del punto).
La soluzione adottata in Èulogos, studiata da Maurizio Amizzoni [Amizzoni 1991], consiste nel costruire un modello
del testo in analisi e su quel modello stabilire i punti di fine frase. Proprio questa
caratteristica consente al sistema di calcolare l'indice GULPEASE con affidabilità
molto elevata.
Lemmatizzazione
- Per lemmatizzazione si intende quel procedimento che noi tutti facciamo quando
incontriamo una parola e la cerchiamo in un dizionario.
Per esempio, chi s'imbattesse nella parola "porto" e non ne conoscesse il
significato, aprirebbe il dizionario e cercherebbe ... che cosa? È proprio qui il
problema: il lettore umano che conosce la lingua italiana, sa bene che se volesse trovare
"porto" dovrebbe cercare "porto", ma anche "portare" e
"porgere", e in base al contesto stabilire quali dei tre vocaboli è quello
giusto, cioè disambiguare. Ma per l'elaboratore non è così semplice: fino ad
oggi, gli elaboratori, per quanto veloci siano e per quanto articolati possano essere i
programmi, non possono capire un testo. Per dirla in modo più scientifico, un elaboratore
non può accedere al piano semantico del testo.
Disambiguare per un programma di elaboratore è un po' come stabilire il colore di oggetti
di forma diversa avendo gli occhi bendati.
- Sono stati fatti diversi tentativi per ottenere, da parte di un programma di
elaboratore, un comportamento analogo a quello della comprensione, almeno per gli aspetti
relativi alla lemmatizzazione. I tentativi fatti, tra i quali molto interessanti quelli
con le reti neurali (vedi [Parisi-Castelfranchi
1987]), sono riusciti a ottenere risultati degni di nota su testi predigeriti, e non
su testi qualsiasi.
- Il problema della comprensione del testo è molto sentito anche per chi si occupa di
traduzione automatica. La Comunità Europea, per esempio, ha investito ingenti risorse in
questo settore (il servizio traduzioni della Comunità Europea è il più grande e
complesso del mondo), ma i programmi non sono ancora sufficientemente affidabili su testi
non controllati, e comunque la traduzione deve essere almeno controllata, e spesso
rivista, da un operatore umano.
- A questi problemi se ne aggiunge un altro. Il programma di un elaboratore lemmatizza in
base a un proprio dizionario di macchina, che contiene i dati morfologici sui lemmi e
altri dati utili. Quando il programma si imbatte in una parola che non corrisponde a
nessuna di quelle che conosce, segnala il fatto all'operatore, che deciderà se inserire
la forma nel sistema (sia come nuovo lemma che come forma di un lemma già noto). Ma che
cosa succede quando la forma appartiene a un lemma non presente nel dizionario di macchina
ed è però omografa a quella di un lemma presente? In questo caso il programma non può
segnalare che la parola è sconosciuta perché la può lemmatizzare, né può segnalare
che appartiene a un lemma che non conosce perché, appunto, non lo conosce.
- In alcuni lemmatizzatori il problema delle lemmatizzazioni possibili ma sconosciute è
stato affrontato creando un meccanismo di predizione, che cerca di ricostruire il lemma di
un'occorrenza anche attraverso regole generali. Questa soluzione, concettualmente valida,
ha l'inconveniente di dare spesso risultati di fantasia, mettendo il lista di frequenza
lemmi inesistenti o impropri ("bottone" alterazione di "botto",
"guanciale" forma con pronome di "*guanciare", ecc.).
La soluzione migliore finora adottata è costruire un dizionario di macchina completo,
cioè tale che per ogni forma riconosciuta siano presenti tutti i lemmi che la possono
produrre. Anche se non è possibile avere l'assoluta certezza della completezza (la lingua
riserva sempre sorprese), tale soluzione permette di ottenere lemmatizzazioni molto
affidabili.
Polirematica
- Intendiamo per polirematica un'espressione che consideriamo come un vero e
proprio lemma. In particolare sono polirematiche:
- espressioni il cui significato non è deducibile dalla somma dei significati delle
singole parole, anche se appartenenti al Vocabolario di
Base, come faccia di bronzo, testa di cuoio, ecc.;
- espressioni cristallizzate nell'uso con sensi particolari, come inquinamento acustico,
deficit pubblico, ecc.;
- espressioni la cui funzione grammaticale non è deducibile dalla classe grammaticale cui
appartengono le singole parole che la formano, come per quanto, nella misura in
cui, ecc.
- La forma di citazione con la quale registriamo una polirematica è di norma la forma che
si ottiene dalle forme di citazione delle parole componenti, a meno che la
cristallizzazione imponga vincoli più stretti. Così testa di cuoio è una
polirematica nella sua forma di citazione, ma anche rompere le uova nel paniere lo
è, poiché *rompere l'uovo nel paniere non è attestata.
Nei casi nei quali la polirematica termina con una preposizione, mettiamo a lemma la forma
con la preposizione non articolata. Così per mezzo di è la forma di citazione
delle polirematiche per mezzo di e per mezzo del. Ugualmente mettiamo a
lemma la forma articolata quando questa fosse cristallizata nella polirematica.
- Registriamo nella forma di citazione della polirematica eventuali segni di punteggiatura
quando costituiscono parte integrante della polirematica stessa, come in vita, morte e
miracoli: in fase di lemmatizzazione è possibile stabilire se la presenza dei segni
di punteggiatura sia da considerarsi discriminante ai fini del riconoscimento della
polirematica.
- Vi sono inoltre molti casi nei quali la polirematica è definita a meno di elisioni,
come in esame di ammissione, che può essere presente anche come esame
d'ammissione. Con tali polirematiche preferiamo registrare la forma senza elisione e
segnalare le varianti in nota e nei dati morfologici del lemma. Tuttavia nei casi nei
quali l'elisione è cristallizzata, mettiamo a lemma l'espressione contenente la forma
elisa, come in testa d'uovo.
Lo stesso accade per i casi di apocope: mettiamo a lemma la forma non apocopata, come in mano
mano - man mano, a meno che non si presentino cristallizzati: a fin di bene,
pian piano, a mo' di esempio.
Nei casi nei quali il passaggio dalla forma semplice alla forma articolata di una
preposizione comporti un cambiamento di rango, le registriamo separatamente: andare coi
piedi di piombo - andare con i piedi di piombo.
- Per le polirematiche verbali che contengono anche la preposizione, come andare pazzo
per, se la polirematica occorre priva di preposizione con lo stesso significato e
senza ambiguità (come nella frase "ne andava pazzo"), registriamo separatamente
la polirematica senza preposizione.
- Per le coppie del tipo a bruciapelo - a brucia pelo, a capofitto - a
capo fitto, ecc., registriamo entrambe le polirematiche e segnaliamo in nota il
rapporto tra le due.
- Un caso a parte è rappresentato da polirematiche che risultano dall'uso cristallizzato
di forme verbali associate a pronomi. Citiamo il caso di cavarsela, polirematica
che nella forma di citazione è costituita da una sola parola, ma che in realtà
rappresenta le polirematiche me la cavo, te la cavi, ecc.
- Vedi anche la definizione di rango
di una polirematica.
Rango (di polirematica)
- Definiamo il rango di una polirematica
come il numero delle parole che la compongono nella forma di citazione. Le forme elise di
articoli, preposizioni e pronomi costituiscono parola a sé stante: testa d'uovo ha
rango tre, a bizzeffe ha rango due, ecc. Consideriamo parola a sé stante anche il
genitivo sassone nelle polirematiche importate dalla lingua inglese.
- Possono essere presenti polirematiche di rango uno, come in polirematiche del tipo cavarsela,
essendo il rango calcolato sulla forma di citazione.
Vocabolario
di Base della lingua italiana
- Il Vocabolario di Base della lingua italiana (VdB) di Tullio De Mauro ([De Mauro 1991]) è un elenco di lemmi elaborato
prevalentemente secondo criteri statistici. Esso rappresenta la porzione della lingua
italiana usata e compresa dalla maggior parte di coloro che parlano italiano.
- La scelta dei lemmi è stata fatta in base ai primi 5.000 lemmi del Lessico Italiano
di Frequenza (LIF) [Bortolini et a. 1972]
(ridotti a circa 4.750 dopo averne verificato la comprensibilità), integrati con un
insieme di lemmi determinati per altre vie. In particolare, i lemmi del VdB sono
classificati in tre livelli:
- Vocabolario fondamentale: i primi 1.991 lemmi del LIF. Sono i lemmi più
frequenti in assoluto della nostra lingua;
- Vocabolario di alto uso: i successivi 2.750 lemmi dell'insieme preso dal LIF. Sono lemmi ancora molto frequenti, anche se
molto meno di quelli del vocabolario fondamentale;
- Vocabolario di alta disponibilità: 2.337 lemmi determinati in vario modo,
soprattutto con dizionari dell'italiano comune. L'integrazione è stata necessaria perché
il LIF è il risultato dello spoglio di testi
scritti, ed è ormai dimostrato che vi è in tutte le lingue un insieme di lemmi che, pur
essendo quasi del tutto assenti nella lingua scritta, sono a tutti noti. Per esempio,
lemmi come forbice, abbronzare, ecc.
- Il VdB è stata la prima opera di questo genere realizzata in Italia (per gli studi
fatti all'estero, vedi [Sciarone 1977]), e a
tutt'oggi è uno strumento d'importanza fondamentale per controllare e migliorare la
leggibilità di un testo secondo criteri scientifici. Infatti le parole che non sono nel
VdB sono meno comprensibili per le persone meno scolarizzate o quelle poco abituate a
leggere, e quindi se si vuole essere sicuri che il testo sia comprensibile a tutti
bisognerebbe usare solo tali parole. Questo non vuol dire che un testo ad alta
leggibilità sia chiuso a nuove parole, ma vuol dire che quando si usa un lemma non di
base, soprattutto quando è un lemma importante per capire il testo, bisogna spiegarne il
significato, usando nella spiegazione solo lemmi presenti nel VdB. Un testo altamente
comprensibile non ha solo questa caratteristica (vedi il fondamentale Fenomenologia
dello scrivere chiaro [Lumbelli 1990]), ma
l'uso del VdB è condizione comunque necessaria.
- Un esempio di scrittura ad alta leggibilità è il mensile Due Parole, edito dal
dipartimento di Scienze del Linguaggio dell'Università di Roma «La Sapienza». I
redattori di Due Parole scrivono articoli usando il VdB e spiegando le parole che
non vi appartengono. Inoltre, la redazione applica anche altri criteri di leggibilità,
attinenti alla grafica (caratteri grandi, illustrazioni che non spezzano il testo, ecc.) e
al modo di disporre i contenuti (riquadri di spiegazione, testo a nuova riga per ogni
frase, ecc.). Stiamo conducendo con Èulogos uno studio statistico sulle prime
quattro annate del mensile (per un totale di circa 140.000 occorrenze).
Contattaci: eulogos@eulogos.it.
Copyright Èulogos srl 1996 - MMDCCXLIX a.u.c.